



In a sequence of articles we compare different NLP techniques to show you how we get valuable information from unstructured text. About a year ago we gathered reviews on Dutch restaurants. We were wondering whether ‘the wisdom of the crowd’ — reviews from restaurant visitors — could be used to predict which restaurants are most likely to receive a new Michelin-star. Read this post to see how that worked out. We used topic modeling as our primary tool to extract information from the review texts and combined that with predictive modeling techniques to end up with our predictions.
We got a lot of attention with our predictions and also questions about how we did the text analysis part. To answer these questions, we will explain our approach in more detail in the coming articles. But we didn’t stop exploring NLP techniques after our publication, and we also like to share insights from adding more novel NLP techniques. More specifically we will use two types of word embeddings — a classic Word2Vec model and a GLoVe embedding model — we’ll use transfer learning with pretrained word embeddings and we use BERT. We compare the added value of these advanced NLP techniques to our baseline topic model on the same dataset. By showing what we did and how we did it, we hope to guide others that are keen to use textual data for their own data science endeavors.
Before we delve into the analytical side of things, we need some prepared textual data. As all true data scientists know, proper data preparation takes most of your time and is most decisive for the quality of the analysis results you end up with. Since preparing textual data is another cup of tea compared to preparing structured numeric or categorical data, and our goal is to show you how to do text analytics, we also want to show you how we cleaned and prepared the data we gathered. Therefore, in this notebook we start with the data dump with all reviews and explore and prepare this data in a number of steps:

As a result of these steps, we end up with — aside from building insights in our data and some cleaning — a number of flat files we can use as source files throughout the rest of the articles:
- reviews.csv: a csv file with review texts (original and cleaned) — the fuel for our NLP analyses. (included key: restoreviewid, hence the unique identifier for a review)
- labels.csv: a csv file with 1 / 0 values, indicating whether the review is a review for a Michelin restaurant or not (included key: restoreviewid)
- restoid.csv: a csv file with restaurant id’s, to be able to determine which reviews belong to which restaurant (included key: restoreviewid)
- trainids.csv: a csv file with 1 / 0 values, indicating whether the review should be used for training or testing — we already split the reviews in train/test to enable reuse of the same samples for fair comparisons between techniques (included key: restoreviewid)
- features.csv: a csv file with other features regarding the reviews (included key: restoreviewid)
These files with the cleaned and relevant data for NLP techniques are made available to you via public blob storage so that you can run all code we present yourself and see how things work in more detail.
Step 0: Setting up our context
First, we set up our workbook environment with the required packages to prepare and explore our data.
In preparing and exploring the data we need two packages: tidyverse and tidytext. As you probably know, tidyverse is the data wrangling and visualization toolkit created by the R legend Hadley Wickham. Tidytext is a ‘tidy’ R package focused on using text. It’s created by Julia Silge and David Robertson and is accompanied with their nice book Text Mining in R.
# Loading packages
library(tidyverse)
library(tidytext)
Step 1: Exploring and preparing our review data
Now, let’s have a look at the data.
# get rawdata
rawdata <- read.csv(file =
'https://bhciaaablob.blob.core.windows.net/cmotionsnlpblogs/RestoReviewRawdata.csv',
header=TRUE,stringsAsFactors = FALSE,row.names = NULL)
Our raw review data consists of 379.718 reviews with in total 28 columns, containing details on the restaurant (name, location, average scores, number of reviews), the reviewer (id, user name, fame, number of reviews) and of course the review (id, scores and — tada- the review text). Here’s an overview:
str(rawdata)
# 'data.frame': 379718 obs. of 24 variables:
# $ restoId : int 255757 255757 255757 255757 255757 255757 255757 255757 255757 255757 ...
# $ restoName : chr "India Palace" "India Palace" "India Palace" "India Palace" ...
# $ tags : chr "Indiaas|zakenlunch|Live muziek|Met familie|Met vrienden|provincie Zuid-Holland|Terras|Tuin" "Indiaas|zakenlunch|Live muziek|Met familie|Met vrienden|provincie Zuid-Holland|Terras|Tuin" "Indiaas|zakenlunch|Live muziek|Met familie|Met vrienden|provincie Zuid-Holland|Terras|Tuin" "Indiaas|zakenlunch|Live muziek|Met familie|Met vrienden|provincie Zuid-Holland|Terras|Tuin" ...
# $ address : chr "Natuursteenlaan 157 2719 TB Zoetermeer Nederland" "Natuursteenlaan 157 2719 TB Zoetermeer Nederland" "Natuursteenlaan 157 2719 TB Zoetermeer Nederland" "Natuursteenlaan 157 2719 TB Zoetermeer Nederland" ...
# $ scoreTotal : chr "8" "8" "8" "8" ...
# $ avgPrice : chr "\u0080 24" "\u0080 24" "\u0080 24" "\u0080 24" ...
# $ numReviews : int 57 57 57 57 57 57 57 57 57 57 ...
# $ scoreFood : chr "8,2" "8,2" "8,2" "8,2" ...
# $ scoreService : chr "7,7" "7,7" "7,7" "7,7" ...
# $ scoreDecor : chr "7,7" "7,7" "7,7" "7,7" ...
# $ review_id : int 1 2 3 4 5 6 7 8 9 10 ...
# $ numreviews2 : int 55 55 55 55 55 55 55 55 55 55 ...
# $ valueForPriceScore : chr "" "" "" "" ...
# $ noiseLevelScore : chr "" "" "" "" ...
# $ waitingTimeScore : chr "" "" "" "" ...
# $ reviewerId : int 111436837 111280499 111271663 123554609 111214501 112751455 111508525 112999071 111358913 120135365 ...
# $ reviewerFame : chr "Fijnproever" "Fijnproever" "Meesterproever" "Proever" ...
# $ reviewerNumReviews : int 3 2 12 1 1 2 1 2 23 1 ...
# $ reviewDate : chr "25 dec. 2017" "17 nov. 2017" "22 aug. 2017" "20 aug. 2017" ...
# $ reviewScoreOverall : chr "9" "10" "7,5" "2,5" ...
# $ reviewScoreFood : int 10 10 8 2 2 10 10 8 10 10 ...
# $ reviewScoreService : int 8 10 6 2 2 8 8 10 10 8 ...
# $ reviewScoreAmbiance: int 8 10 8 4 6 8 6 8 10 2 ...
# $ reviewText : chr "b'Heerlijk eten en leuke sfeer. Veel keuze bij het buffet en toetjes ook heel goed. Werd steeds aangevuld en wa"| __truncated__ "b\"Met z'n vieren dit restaurant bezocht. We hadden de Butter Chicken, de mixed grill en groente besteld.\\nHet"| __truncated__ "b'Snel gegeten tijdens een plotselinge bezoek naar Zoetermeer. eten was niet zo bijzonder. Maar ja, als je hon"| __truncated__ "b'Wait to be seated! We moesten lang wachten.Ontvangen door spraakloze ober, kwam met volle mond uit de keuken"| __truncated__ ...
For now, we’re primarily interested in the review text. Aside from those, we only need to keep some ids to match our reviews to restaurants and to Michelin restaurants later on. To get an impression of what we’ll be working with, let’s look at some review texts:
# look at some example texts
rawdata %>% select(reviewText) %>% sample_n(5,seed=1234) %>% pull()
[1] "b'4 gangen menu genomen en stokbrood vooraf.\\nEerste gerecht te snel terwijl het stokbrood er nog niet was als vooraf.\\nbij 4 de gang de bijpassende wijn vergeten.\\nBij controle kassa bon teveel berekend!!\\nToen ook nog mijn jas onvindbaar.'"
[2] "b'Onkundige bediening die je onnodig laat wachten en geen overzicht heeft en niet attent is. Kippenpasteitje was met 1 eetlepel ragout gevuld. Daarentegen zeer pittige prijzen. Sanitaire voorzieningen erbarmelijk. Tafeltjes smerig.'"
[3] "b'lekkere pizza in nieuwe winkel ,inrichting sober maar hoort denk ik bij het concept , vriendelijk personeel en voor ons in de buurt'"
[4] "b\"Ik was al weleens bij hun andere vestiging geweest aan de Goudsesingel en ze hebben wel dezelfde kaart,maar voor de rest lijken ze niet echt op elkaar.Ik deze veel leuker.Sowieso ziet het er echt heel leuk uit van binnen.100% Afrikaans en als het donker is buiten zie je dat het heel sfeervol verlicht is.Zelden in zo'n gezellig uitziend tentje gegeten.Ze hebben er echt werk van gemaakt.Tafeltjes staan allemaal goed opgesteld,je hebt de ruimte.Ook de (Afrikaanse?) bediening liep nog in een Afrikaans tijgervelletje en het Afrikaanse muziekje op de achtergrond maakte het helemaal compleet.Ik koos vooraf voor de linzensoep.Had dat nog nooit op,klinkt misschien een beetje saai gerecht,maar het is echt een aanrader.Lekker pittig ook! Mijn vriend had krokodillensate,niet echt mijn ding,heb wel geproefd,maar beetje taai vlees,maar dat hoort misschien wel gewoon.Als hoofdgerecht is het het leukst om schotel Heweswas te nemen,omdat je dan van alles wat krijgt en je mag lekker met je handen eten! Dat maak je niet vaak mee in een restaurant natuurlijk.Het is een grote leuke uitziende schotel en je krijgt er een soort pannekoekjes bij om het eten mee te pakken.Ik ben geen visliefhebber,maar die vis die erbij zat luste ik zowaar wel en ik vond hem nog lekker ook.De pompoen en (soort van) rijst erbij was echt heerlijk.Allen die aardappel die erbij zat leek wel een steen.En 1 van de 2 rund was erg taai en droog,maar voor de rest echt super deze schotel.Ook lekker veel.Ideaal als je geen keuzes kan maken,je krijgt toch van alles.Ze hebben ook fruitbier bijv mango bier,dat drink je dan uit een heel leuk kommetje.Als toetje koos ik voor de tjakrie.Lekker fris!Ik twijfelde nog omdat er yoghurt inzat,maar dat overheerste gelukkig niet,het was lekker zoet.Mijn vriend koos voor de gebakken banaan,maar die is anders als je denkt : beetje oliebol-achtig,ook echt heel lekker.Enige minpunt die ik kan bedenken: het voorgerecht duurde erg lang en ze kwamen ook geen 1 keer uit hunzelf vragen of we nog drinken wilde.Terwijl de zaak toch maar voor een derde gevuld was.Het gaat er allemaal 'relaxed' aan toe,maar dat hoort natuurlijk ook bij een Restaurant dat Viva Afrika heet natuurlijk.Maar je moet geen haast hebben dus,en dat hadden wij ook niet gelukkig, Ja echt een leuk restaurant dit!\""
[5] "b'Ik ga hier vaak met vrienden even een hapje eten of borrelen. Erg leuke tent, heerlijk eten en de bediening is altijd vrolijk en attent! Zowel een leuke menu- als borrelkaart en lekkere wijnen per glas. Aanrader: de gehaktballetjes met truffelmayo voor bij de borrel en de cote du boeuf die er soms als dagspecial is.'"
Ok, there’s clearly some cleaning to be done here.
First of all, the available texts are all encapsulated in “b’…’’”, indicating the texts are byte literals. Also you might spot some strange sequences of tokens like in ‘ingredi\xc3\xabnten’, indicating that our texts include UTF-8 encoded tokens (here, the character ë that has the code \xc3\xab in UTF-8). This combination of byte literal encapsulation with the UTF-8 codes shows that in the creation of the source data we have available, the encoding got messed up a bit, making it difficult to to obtain the review texts out of the encoded data. We won’t go in to too much detail here (if you want, read this) but you might run into similar stuff when you start working with textual data. In short, there are different encoding types and you need to know what you are working with. We need to make sure we use the right encoding and we should get rid of the “b’…’’” in the strings.
We could spend some time on figuring out how to correct this messing-up due to coding as good as possible. However, in order not to lose too much time and effort on undoing this, we can take a short cut with minimal loss of data by cleaning the texts with some regular expressions (with the gsub() function in the code below). Depending on your goal, you might want to go the extra mile and try to restore the texts in their original UTF-8 encoding though! As so often in data science projects, we’re struggling with available time and resources: You need to pick you battles — and pick them wisely!
Do we have other things to cover? To get a better understanding of our data, let’s check the most frequent, identical review texts:
rawdata %>%
group_by(reviewText) %>%
summarize(n_reviews=n()) %>%
mutate(pct=n_reviews/sum(n_reviews)) %>%
arrange(-n_reviews) %>%
top_n(10,n_reviews)
# A tibble: 10 x 3
reviewText n_reviews pct
<chr> <int> <dbl>
1 "" 11189 0.0295
2 "b'- Recensie is momenteel in behandeling -'" 1451 0.00382
3 "b'Heerlijk gegeten!'" 382 0.00101
4 "b'Heerlijk gegeten'" 293 0.000772
5 "b'Heerlijk gegeten.'" 165 0.000435
6 "b'Top'" 108 0.000284
7 "b'Lekker gegeten'" 85 0.000224
8 "b'Prima'" 72 0.000190
9 "b'Top!'" 61 0.000161
10 "b'Lekker gegeten!'" 60 0.000158
Ok, several things to solve here:
- About 3% of all reviews have no review text so they are not useful and we can delete those.
- Another 0,4% has the value “b’- Recensie is momenteel in behandeling -’” (In English: The review is currently being processed) and therefore the actual review text is not published yet. Similar to empty reviews, we can delete these reviews.
- We see several frequent review texts that only differ in punctuation. Here we make our next decision with possibly high impact on later analysis steps: We remove punctuation entirely from our data. Since we want to focus on total review texts in our analyses and not on the sentences within reviews, this is ok for us. For other analyses, this might not be the case!
- Several reviews seem very short and are not that helpful in trying to learn from the review text. Although this is very context dependent (when performing sentiment analysis, short reviews like ‘Top!’ (English: Top!), ‘Prima’ (Engish: Fine/OK) and ‘Heerlijk gegeten’ (En: Had a nice meal) might still have much value!) we have to set a minimum length to reviews.
data <- rawdata %>%
#remove metatext ('b:'), replace linebreaks and some punctuation with space
# and remove other punctuation and set to lower case.
mutate(reviewTextClean=gsub('[[:punct:]]+', '',
gsub('\\\\n|\\.|\\,|\\;',' ',tolower(substr(reviewText,3,nchar(reviewText)-1))))) %>%
# create indicator validReview that is 0 for reviews to delete
mutate(validReview=case_when(# unpublished review texts
grepl('recensie is momenteel in behandeling',reviewTextClean)~0,
# review texts less than 2 characters in length
nchar(reviewTextClean) <2 ~ 0,
# review texts of length 2, not being 'ok'
nchar(reviewTextClean)==2 &
grepl('ok',reviewTextClean)==FALSE ~ 0,
# review texts of length 3, not being 'top','wow','oke'
nchar(reviewTextClean) ==3 &
grepl('top|wow|oke',reviewTextClean)==FALSE ~ 0,
TRUE ~ 1))
After removing punctuation and lowcasing our texts let’s check what are the review texts we’re about to remove. Also, let’s see what are most frequent full review texts we are planning to keep for now:
# check most frequent reviews (and indicator to drop or not)
data %>%
group_by(reviewTextClean,validReview) %>%
summarize(n_reviews=n()) %>%
group_by(validReview) %>%
arrange(validReview,desc(n_reviews)) %>%
top_n(5,n_reviews)
# A tibble: 10 x 3
# Groups: validReview [2]
reviewTextClean validReview n_reviews
<chr> <dbl> <int>
1 "" 0 11275
2 " recensie is momenteel in behandeling " 0 1451
3 " " 0 42
4 "nvt" 0 39
5 " " 0 12
6 "heerlijk gegeten" 1 786
7 "heerlijk gegeten " 1 216
8 "top" 1 196
9 "lekker gegeten" 1 178
10 "prima" 1 134
Looking all right, we drop the reviews with a 0 on validReview. To be able to identify unique reviews later, we also create a unique identifier. While we’re at it, we also do some other cleaning on some features we might need later on.
data <- data %>%
# remove all reviews that are not valid accoring to our rules defined earnier
filter(validReview==1) %>%
mutate(#create a unique identifier by combining the restaurant-id
# and the review-id that identifies unique reviews within a restaurant
restoReviewId = paste0(restoId,'_',review_id),
#some extra preparation on other features we have available:
reviewDate = lubridate::dmy(reviewDate),
yearmonth=format(reviewDate,'%Y%m'),
waitingTimeScore = recode(waitingTimeScore,"Kort"=1, "Redelijk"=2,
"Kan beter"=3, "Hoog tempo"=4, "Lang"=5, .default=0, .missing = 0),
valueForPriceScore = recode(valueForPriceScore,"Erg gunstig"=1, "Gunstig"=2,
"Kan beter"=3, "Precies goed"=4, "Redelijk"=5, .default=0, .missing = 0),
noiseLevelScore = recode(noiseLevelScore,"Erg rustig"=1, "Precies goed"=2,
"Rumoerig"=3, "Rustig"=4, .default=0, .missing = 0),
scoreFood = as.numeric(gsub(",", ".", scoreFood)),
scoreService = as.numeric(gsub(",", ".", scoreService)),
scoreDecor = as.numeric(gsub(",", ".", scoreDecor)),
reviewScoreOverall = as.numeric(gsub(",", ".", reviewScoreOverall)),
scoreTotal = as.numeric(gsub(",", ".", scoreTotal)),
reviewTextLength = nchar(reviewTextClean)
)
Step 2: Preparing our data on the token level
Now that we’ve done some cleaning on the review level we can look at the token level more closely. In NLP lingo, a token is a string of contiguous characters between two spaces. Therefore, we have to split our full review texts into sets of tokens. Next, we can answer questions like: How long should a review be to be of any value to us when we want to identify topics in the reviews? And: Do we want to use all tokens or are some tokens not that relevant for us and is it better to remove them?
Here, we’ll use the tidytext package for the first time, for tokenizing the review texts we have prepared. Tokenizing means splitting the text into separate tokens (here: words). After unnesting the tokens from the texts, we can evaluate the length of our restaurant reviews.
## divide text into separate words
reviews_tokens <- data %>%
select(restoReviewId, reviewTextClean) %>%
unnest_tokens(word, reviewTextClean)
reviews_tokens %>%
group_by(restoReviewId) %>% summarise(n_tokens = n()) %>%
mutate(n_tokens_binned = cut(n_tokens, breaks = c(0,seq(25,250,25),Inf))) %>%
group_by(n_tokens_binned) %>% summarise(n_reviews = n()) %>%
ggplot(aes(x=n_tokens_binned,y=n_reviews)) +
geom_bar(stat='identity',fill='blue') + theme_minimal()
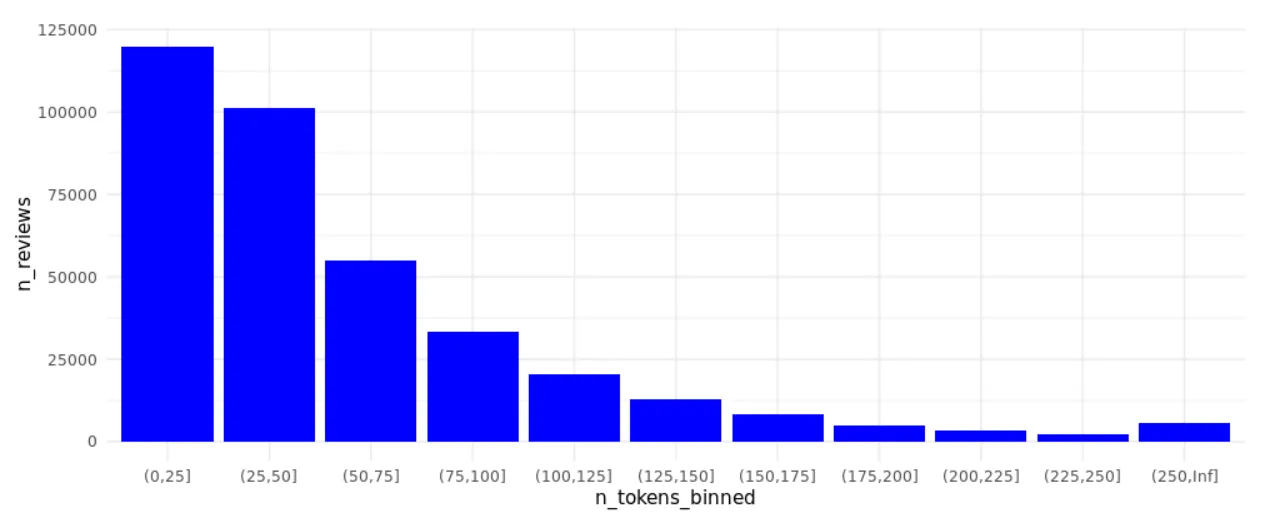
We’re about to make a second decision with high impact on future analysis results: We only keep reviews with more than 50 tokens. This seems like a lot of information we’re throwing away, however we expect that these short reviews won’t help us much in identifying different topics within reviews. By doing so, we focus on ~40% of all reviews available, still around 145K reviews in total to work with:
# count the reviews that have at least 50 tokens
reviews_tokens <- reviews_tokens %>% group_by(restoReviewId) %>%
mutate(n_tokens = n(),review_50tokens_plus = case_when(n_tokens > 50 ~1, TRUE ~ 0))
reviews_tokens %>% group_by(review_50tokens_plus) %>%
summarize(n_reviews = n_distinct(restoReviewId)) %>%
mutate(pct_reviews = n_reviews/sum(n_reviews))
# A tibble: 2 x 3
review_50tokens_plus n_reviews pct_reviews
<dbl> <int> <dbl>
1 0 220917 0.602
2 1 145867 0.398
# aaaaaaaaaaaaaand, they are gone..............
reviews_tokens <- reviews_tokens %>% filter(n_tokens>50)
Something to consider: Stemming & Lemmatization
Another possibly impactful text preprocessing step is stemming and lemmatizing your tokens. In short: This means trying to make your tokens more generic by replacing it by a more generic form. For plurals (e.g. restaurants) this would mean replacing it with singulars (restaurant), for verbs (tasting) to the root of the verb (taste). With stemming, the last part of the word is cut off to bring it to its more generic form, with lemmatization this is done a bit more thorough by taking into consideration the morphological analysis of the words. Both techniques have their pros and cons — computationally and in the usefulness of the resulting tokens — and depending on your research question you can choose to apply one or the other. Or you can decide that it’s doing more harm than good in your case. After some explorations and literature reviews on Dutch stemming and Lemmatization techniques, we decided not to apply either stemming or lemmatization here. Again, in another context, we might choose differently. Since you should at least consider this possibly impactful textual data preparation step, we did want to mention it here as we also did consider it.
Stop words
Now that we have our sets of prepared tokens, we need to specify which tokens won’t be that useful to keep. In many cases, stop words have no added value and we’re better off without them. Not always, especially not when your analysis focusses on the exact structure of the text or when you are specifically interested in the use of specific highly frequent words including stop words. Also, in sentiment analysis, usage of stop words might be relevant. However, we primarily want to distill the topics discussed by reviewers in the reviews. As a result, we’re happy to focus on those terms that are not too frequent and tokens that help in revealing information relevant to our restaurant review context.
There are — in many languages — many nice sources of stop words available. You can easily get your hands on these and use them as a basis for your own list of stopwords. In our experience, it is however wise to review and edit such a list of potential stop words carefully. We collected and customized the stop words from the stopwords library, containing many of these curated lists of stop words from various sources in various languages.
# get stopwords from package stopwords
stopwords_sw_iso <-stopwords::stopwords(language = 'nl',source='stopwords-iso')
cat(paste0('Number of stop words from package stopwords (source=stopwords-iso): ',length(stopwords_sw_iso),'\n\n'))
cat(paste0('First 50 stop words: ',paste(stopwords_sw_iso[1:50], collapse=', '),', ...'))
Number of stop words from package stopwords (source=stopwords-iso): 413
First 50 stop words: aan, aangaande, aangezien, achte, achter, achterna, af, afgelopen, al, aldaar, aldus, alhoewel, alias, alle, allebei, alleen, alles, als, alsnog, altijd, altoos, ander, andere, anders, anderszins, beetje, behalve, behoudens, beide, beiden, ben, beneden, bent, bepaald, betreffende, bij, bijna, bijv, binnen, binnenin, blijkbaar, blijken, boven, bovenal, bovendien, bovengenoemd, bovenstaand, bovenvermeld, buiten, bv, ...
When reviewing these stopwords, we found that some could be quite relevant in our context of identifying topics people discuss when reviewing their restaurant experience. Words like gewoon (could mean plain), weinig (little food? little taste?), buiten (outside?) might be relevant and we don’t want to drop those.
# keep some stopwords
excludefromstopwords <- c('gewoon', 'weinig', 'buiten', 'genoeg', 'samen', 'precies',
'vroeg', 'niemand', 'spoedig')
stopwords_sw_iso <- stopwords_sw_iso[!stopwords_sw_iso %in% excludefromstopwords]
cat(paste0('Number # of stop words after removing ',length(excludefromstopwords),
' stop words: ',length(stopwords_sw_iso),'\n\n'))
#add new stopwords
extra_stop_words <- c('zeer', 'echt', 'goede', 'keer', 'terug', '2', 'helaas', '3','hele',
'allemaal', 'helemaal', '1', 'mee', 'elkaar', 'fijne', '4', 'graag','best', 'erbij', 'echte',
'fijn', 'qua', 'kortom', 'nde', '5', 'volgende','waardoor','extra', 'zowel', '10', 'soms',
'nhet', 'heen', 'ontzettend','zn', 'regelmatig', 't', 'uiteindelijk', '6', 'diverse',
'xc3xa9xc3xa9n','absoluut', 'xe2x82xac', 'langs', 'keren', 'meerdere', 'direct', 'ok',
'mogelijk','waarbij', 'daarbij', 'a', '8', 'behoorlijk', 'enorm', '7','20', 'redelijke',
'alsof', 'n', 'nou', 'ver', 'vele', 'oa', 'uiterst', '15','2e', 'absolute','ipv','all','ter',
'you', 'wellicht', 'vast','name', 'den','the', 'midden', 'min','dezelfde', 'waarvan', 'can',
'ten','bijvoorbeeld','eat', '9', 'x', 'vaste', '25', 'uiteraard', 'zie','pp','30','allerlei',
'enorme', 'nwij', 'okxc3xa9', 'erop', 'nik', 'ronduit', 'eenmaal','ivm', '50','s','hierdoor',
'evenals', 'neen', 'nogmaals', 'hoor', '2x', 'allen', 'wijze','uitermate', 'flink', '12',
'doordat', 'mn', 'achteraf', 'flinke', 'daarvoor','ene', 'waarop', 'daarentegen', 'ervoor',
'momenteel','tevens', 'zeg', 'mede' )
# create dataframe with stop words and indicator (useful for filtering later on)
stop_words <- data.frame(word=unique(c(stopwords_sw_iso,extra_stop_words)),stringsAsFactors=F)
stop_words <- stop_words %>% mutate(stopword=1)
cat(paste0('Number of stop words after including ',length(extra_stop_words),
' extra stop words: ',sum(stop_words$stopword)))
Number # of stop words after removing 9 stop words: 404
Number of stop words after including 128 extra stop words: 532
We’re ready to drop the stop words. With a few printed reviews we can see that the total text has become more dense and a bit less readable to the human eye. However, as a result we now focus more on the relevant tokens in the review texts.
Let’s check the difference with and without our stopwords as we go, to get an impression of the impact.
# First, let's check how a random review text looked before removing stopwords...
examplereview = reviews_tokens %>% ungroup() %>% distinct(restoReviewId) %>%
sample_n(size=1,seed=1234)
data %>% filter(restoReviewId==pull(examplereview)) %>% select(reviewText) %>%
pull() %>% paste0('\n\n') %>% cat()
# remove stopwords
reviews_tokens_ex_sw <- reviews_tokens %>%
left_join(y=stop_words, by= "word", match = "all") %>% filter(is.na(stopword))
# ... and recheck how that review text looks after removing stopwords
reviews_tokens_ex_sw %>% filter(restoReviewId==examplereview) %>%
summarize(reviewText_cleaned=paste(word,collapse=' ')) %>% pull() %>% cat()
b'Onze verwachtingen zijn niet helemaal uitgekomen. Wij hadden er meer van verwacht. In de details van bediening, accuratesse en algehele kwaliteit mag je van een restaurant in deze prijsklasse meer verwachten. Onze opmerkingen/vragen over gerechten en temperatuur van de wijn werden erg gemakkelijk afgedaan. Bij de koffie een suikerpot gevuld met een minimalistisch bodempje suiker op tafel zetten, roept vraagtekens op over de attentiewaarde.'
verwachtingen uitgekomen verwacht details bediening accuratesse algehele kwaliteit restaurant prijsklasse verwachten opmerkingenvragen gerechten temperatuur wijn gemakkelijk afgedaan koffie suikerpot gevuld minimalistisch bodempje suiker tafel zetten roept vraagtekens attentiewaarde
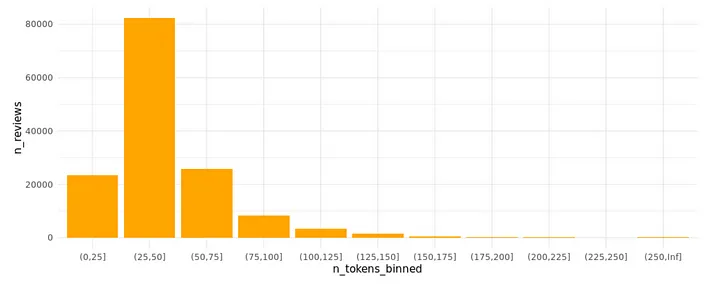
As this single example already shows, the number of tokens and thereby the review lengths have decreased, but the essential words are still present in the texts. Reading the text has become a bit more troublesome, though. Luckily we’re going to use appropriate NLP techniques soon, enabling us to exact the essence of the reviews. Rerunning the review text length plot confirms that our reviews have shrunk in size:
# check new lengths after removing stop words
reviews_tokens_ex_sw %>%
group_by(restoReviewId) %>% summarise(n_tokens = n()) %>%
mutate(n_tokens_binned = cut(n_tokens, breaks = c(0,seq(25,250,25),Inf))) %>%
group_by(n_tokens_binned) %>% summarise(n_reviews = n()) %>%
ggplot(aes(x=n_tokens_binned,y=n_reviews)) +
geom_bar(stat='identity',fill='orange') + theme_minimal()
Adding Bigrams
So far we only talked about tokens as single words, but combinations of subsequent words — named bigrams for two adjacent words and trigrams for three — are also very useful tokens in many NLP tasks. Especially in English because, compared to other languages, words that belong together are often not combined in one token in English, like table cloth and waiting room whereas they are in other languages like Dutch (tafellaken and wachtkamer). Nevertheless, also in Dutch bigrams and trigrams are of value and for some NLP techniques we do use them.
In the previous step, we identified and removed stopwords. Since we defined these terms to be irrelevant, we also want to remove bigrams for which at least one of the tokens is a stop word. We do need to perform identification of relevant bigrams on the texts prior to removing stopwords, otherwise we end up with many bigrams that actually were not present in the text but are a result of removing one or more intermediary terms. Hence, we go back to the texts with the stopwords included, create bigrams and only keep bigrams when no stop word is present in either of the terms in the bigram:
# create bigrams with the unnest_tokens function, specifying the ngram lenght (2)
bigrams <- reviews_tokens %>%
group_by(restoReviewId) %>%
summarize(reviewTextClean=paste(word,collapse=' ')) %>%
unnest_tokens(bigram, token = "ngrams",n = 2, reviewTextClean)
print(paste0('Total number of bigrams: ',dim(bigrams)[1]))
#remove bigrams containing stopwords
bigrams_separated <- bigrams %>%
separate(bigram, c('word1', 'word2'), sep=" ")
bigrams_filtered <- bigrams_separated %>%
filter(!word1 %in% stop_words$word & !word2 %in% stop_words$word)
bigrams_united <- bigrams_filtered %>%
unite(bigram, word1, word2, sep = '_')
print(paste0('Total number of bigrams without stopwords: ',dim(bigrams_united)[1]))
# show most frequent bigrams
top10_bigrams = bigrams_united %>% group_by(bigram) %>% summarize(n=n()) %>%
top_n(10,wt=n) %>% select(bigram) %>% pull()
print(paste0('Most frequent bigrams: ',paste(top10_bigrams,collapse=", ")))
[1] "Total number of bigrams: 15703075"
[1] "Total number of bigrams without stopwords: 2303146"
[1] "Most frequent bigrams: gaan_eten, gangen_menu, heerlijk_gegeten, herhaling_vatbaar, lang_wachten, lekker_eten, lekker_gegeten, prijs_kwaliteit, prijskwaliteit_verhouding, vriendelijke_bediening"
When saving the prepared review text data, we’ll combine the unigrams and bigrams. Since bigrams are not that useful in all other NLP techniques, we keep the bigrams in a separate field so we can easily include or exclude them when using different NLP techniques.
Extra feature: Review Sentiment
Later on, we will combine the features we get from applying NLP techniques to the review texts with other features about the review. Earlier, we already did a bit of cleaning on some of the extra features, here we add a sentiment score to each review. Sentiment analysis is a broad field within NLP and can be done in several ways. Here, we take advantage of pretrained international sentiment lexicons that are made available by the Data Science Lab under GNU GLP license. They provide lists of positive and negative words in many languages; using these lists we calculate a sentiment score by summing all positive words (+1) and all negative words (-1) and standardizing by the total number of positive/negative words in the text.
#read in sentiment words from Data Science Lab
# (https://sites.google.com/site/datascienceslab/projects/multilingualsentiment)
positive_words_nl <-
read_csv("https://bhciaaablob.blob.core.windows.net/cmotionsnlpblogs/positive_words_nl.txt",
col_names=c('word'),col_types='c') %>% mutate(pos=1,neg=0)
negative_words_nl <-
read_csv("https://bhciaaablob.blob.core.windows.net/cmotionsnlpblogs/negative_words_nl.txt",
col_names=c('word'),col_types='c') %>% mutate(pos=0,neg=1)
#combine positive and negative tokens and print statistics
sentiment_nl <- rbind(positive_words_nl, negative_words_nl)
sentiment_nl %>% summarize(sentiment_words=n_distinct(word),positive_words=sum(pos),
negative_words=sum(neg)) %>% print()
# score sentiment for review texts
review_sentiment <- data %>% select(restoReviewId, reviewTextClean) %>%
unnest_tokens(word, reviewTextClean) %>% left_join(sentiment_nl,by='word') %>%
group_by(restoReviewId) %>% summarize(positive=sum(pos,na.rm=T),negative=sum(neg,na.rm=T)) %>%
mutate(sentiment = positive - negative, sentiment_standardized =
case_when(positive + negative==0~0,TRUE~sentiment/(positive + negative)))
# plot histogram of sentiment score
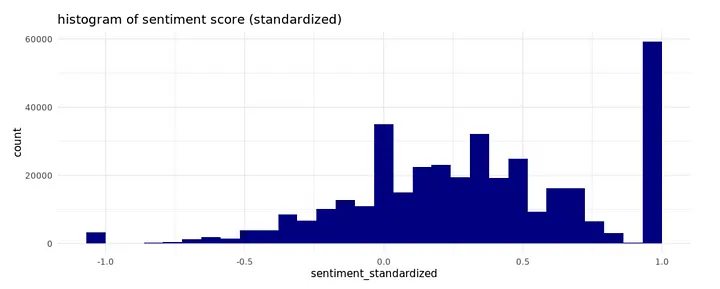
review_sentiment %>% ggplot(aes(x=sentiment_standardized))+ geom_histogram(fill='navyblue') +
theme_minimal() +labs(title='histogram of sentiment score (standardized)')
Is that it? How about….
Yes, for now and for this analysis, this is all the generic textual data preparation we want to apply. You might have expected some other frequently used textual data manipulation techniques here, but we stop our textual data preparation here since we want to put enough of our sparse time and resources available in the next steps: text analytics! We are confident that we did what we needed to do, with our topic modeling in mind. Yes, again that mantra: Pick your battles, and pick them wisely!
Step 3: Saving the prepared review text data
Now that we’ve analyzed, filtered and cleaned our review texts, we can save the files as discussed in the beginning of this blog. So we can use them as our starting point in our next blogs.
reviews.csv
csv file with review texts (original and cleaned) — the fuel for our NLP analyses. (included key: restoreviewid, hence the unique identifier for a review)
To generate a csv with only the restoReviewId and the cleaned review text, we take our processed reviews_tokens dataframe, group by the restoReviewId and combine the tokens into a text again.
# original review text
reviewText <- data %>% select(restoReviewId,reviewText)
# add cleaned review text
reviewTextClean <- reviews_tokens_ex_sw %>% group_by(restoReviewId) %>%
summarize(reviewTextClean=paste(word,collapse=' '))
# add bigrams without stopwords
reviewBigrams <- bigrams_united %>% group_by(restoReviewId) %>%
summarize(bigrams=paste(bigram,collapse=' '))
# combine original review text with cleaned review text
reviews <- reviewText %>% inner_join(reviewTextClean,by='restoReviewId') %>%
left_join(reviewBigrams,by='restoReviewId')
#write to file
write.csv(reviews,'reviews.csv',row.names=FALSE)
labels.csv
csv file with 1 / 0 values, indicating whether the review is a review for a Michelin restaurant or not (included key: restoreviewid)
We want to predict Michelin reviews based on the topics in the review texts. But how do we know a review is a review for a restaurant that has (had) a Michelin star?
To be able to do so, some data ground work needed to be done. We had to delve through several sources with the names and addresses of Dutch Michelin restaurants over the past few years. Next, that list needed to be combined with the restaurants in our restaurant review source. Due to name changes, location changes and other things preventing automatic matching, this was mainly done by hand. This results in a list of restoIds (restaurant ids) that are restaurants that currently have or recently have had one or more Michelin stars (not Bib Gourmand or any other Michelin acknowledgement, only the stars count!).
The csv file contains an indicator (1 / 0) named ind_michelin that tells whether a review (restoReviewId) is a review for a restaurant that is a Michelin restaurant. Hence, this file is already on the restoReviewId level and can easily be combined with the reviews.csv file.
# read file with Michelin restoIds
michelin <- read.csv(file =
'https://bhciaaablob.blob.core.windows.net/cmotionsnlpblogs/michelin_RestoIds.csv',
header=TRUE,row.names = 'X')
# create dataframe with per restaurant an indicator to specify it is a Michelin restaurant
df_michelin <- data.frame(restoId=michelin,ind_michelin=1)
cat(paste0('Number of Michelin restaurants in dataset: ',nrow(df_michelin)))
Number of Michelin restaurants in dataset: 120
# create dataframe with michelin indicator per review (filter reviews with prepared reviewText)
labels <- data %>% inner_join(reviews,by='restoReviewId') %>%
left_join(df_michelin,by='restoId') %>% select(restoReviewId,ind_michelin) %>%
mutate(ind_michelin=replace_na(ind_michelin,0))
#count # of michelin reviews (and % of reviews that is for michelin restaurant)
cat(paste0('Number of Michelin restaurant reviews: ',sum(labels$ind_michelin),' (',
scales::percent(sum(labels$ind_michelin)/nrow(labels),accuracy=0.1),' of reviews)'))
#save csv
write.csv(labels,'labels.csv',row.names=FALSE)
Number of Michelin restaurant reviews: 4313 (3.0% of reviews)
restoid.csv
csv file with restaurant id’s, to be able to determine which reviews belong to which restaurant (included key: restoreviewid)
To evaluate how good our predictions of Michelin / Non-Michelin are on the restaurant level, we need to know what reviews are for the same restaurant. This file contains the restoReviewId and the RestoId.
# select ids for restaurant reviews and restaurants from prepared data
# (filter reviews with prepared reviewText)
restoid <- data %>% inner_join(reviews,by='restoReviewId') %>% select(restoReviewId,restoId)
# save to file
write.csv(restoid,'restoid.csv',row.names=FALSE)
trainids.csv
csv file with 1 / 0 values, indicating whether the review should be used for training or testing — we already split the reviews in train/test to enable reuse of the same samples for fair comparisons between techniques (included key: restoreviewid)
Since the proportion of Michelin Restaurants is low, sampling might have a significant impact on the results of our NLP based models. To be able to compare results fairly, we already split the available reviews into reviews to be used for training and those to be used for testing our models.
# gerenate a sample of 70% of restoReviews, used for training purposes
# (filter reviews with prepared reviewText)
set.seed(101)
sample <- sample.int(n = nrow(data), size = floor(.7*nrow(data)), replace = F)
data$train = 0
data$train[sample] = 1
trainids = data %>% inner_join(reviews,by='restoReviewId') %>% select(restoReviewId,train)
# save to file
write.csv(trainids,'trainids.csv',row.names=FALSE)
features.csv
csv file with other features regarding the reviews (included key: restoreviewid)
In the raw review data, we have more than only review texts available: details on the restaurant (name, location, average scores, number of reviews), the reviewer (id, user name, fame, number of reviews) and on the review (review scores). We want to focus on NLP to show you how to do that, but we also want to show you how to combine features created with NLP techniques with other features you might be more familiar with: numeric and categorical features. In the next blogs where we combine the derived text features with these other features, we will load this csv.
# add sentiment score and select key and relevant features
features <- data %>%
inner_join(review_sentiment,by='restoReviewId') %>%
select(restoReviewId, scoreTotal, avgPrice, numReviews, scoreFood, scoreService,
scoreDecor, reviewerFame, reviewScoreOverall,reviewScoreFood, reviewScoreService,
reviewScoreAmbiance, waitingTimeScore, valueForPriceScore, noiseLevelScore,
reviewTextLength,sentiment_standardized)
# save to file
write.csv(features,'features.csv',row.names=FALSE)
Reading the files, ready to start analyzing!!
Here’s some code to read all the created files. Happy analyzing!!
# **reviews.csv**: a csv file with review texts - the fuel for our NLP analyses. (included key: restoreviewid, hence the unique identifier for a review)
reviews <- read.csv(file = 'https://bhciaaablob.blob.core.windows.net/cmotionsnlpblogs/reviews.csv',header=TRUE,stringsAsFactors=FALSE)
# **labels.csv**: a csv file with 1 / 0 values, indicating whether the review is a review for a Michelin restaurant or not (included key: restoreviewid)
labels <- read.csv(file = 'https://bhciaaablob.blob.core.windows.net/cmotionsnlpblogs/labels.csv',header=TRUE,stringsAsFactors=FALSE)
# **restoid.csv**: a csv file with restaurant id's, to be able to determine which reviews belong to which restaurant (included key: restoreviewid)
restoids <- read.csv(file = 'https://bhciaaablob.blob.core.windows.net/cmotionsnlpblogs/restoid.csv',header=TRUE,stringsAsFactors=FALSE)
# **trainids.csv**: a csv file with 1 / 0 values, indicating whether the review should be used for training or testing - we already split the reviews in train/test to enable reuse of the same samples for fair comparisons between techniques (included key: restoreviewid)storage_download(cont, "blogfiles/labels.csv",overwrite =TRUE)
trainids <- read.csv(file = 'https://bhciaaablob.blob.core.windows.net/cmotionsnlpblogs/trainids.csv',header=TRUE,stringsAsFactors=FALSE)
# **features.csv**: a csv file with other features regarding the reviews (included key: restoreviewid)
features <- read.csv(file = 'https://bhciaaablob.blob.core.windows.net/cmotionsnlpblogs/features.csv',header=TRUE,stringsAsFactors=FALSE)
This article is of part of our NLP with R series. An overview of all articles within the series can be found here.
- Next up in this series: Topic Modeling
Do you want to do this yourself? Please feel free to download the Databricks Notebook or the R-script from out gitlab page.


