



Hoe zorg je voor bewustwordingen en het opnemen van ethiek in jouw datagedreven organisatie?
Het bedrijfsleven kan nu al tijden niet meer zonder data: begrippen als data literacy en datagedreven werken zijn gemeengoed geworden, om nog maar te zwijgen over machine learning en AI. Er wordt meer en meer vertrouwd op data in het maken van dagelijks beslissingen. Hiermee neemt de aandacht toe voor het maken van eerlijke en verantwoorde datagedreven beslissingen. Dat is terecht, want de schade van onethische beslissingen kan groot zijn voor de betrokkenen en daarmee je eigen organisatie.
Dit is een bekende worsteling: op een ethische manier datagedreven werken implementeren. Dit gaat veel verder dan alleen kijken naar de resultaten van bijvoorbeeld een voorspelmodel. Ethisch werken komt terug in iedere stap van een proces en dit maakt dat iedere medewerker hier verantwoordelijk voor is en mee bezig zou moeten zijn. Een goed begrip van ethisch datagedreven werken is essentieel voor elke medewerker binnen je organisatie.
Ethiek als begrip kan nauw samenhangen met regelgeving zoals opgenomen in de Algemene verordening gegevensbescherming (AVG). Hierbij valt bijvoorbeeld te denken aan het in eerste instantie verkrijgen van toegang tot de gegevens (wie of welke rol mag welke gegevens inzien?), maar ook welke data mag worden gebruikt en voor hoe lang. In dit artikel richten we ons bewust niet op deze specifieke regelgeving, maar leggen we de nadruk op ethiek als doorlopend proces.
Dit doen we door je mee te nemen in een stappenplan om ethiek als design principle in te zetten in jouw datagedreven processen. Hiervoor gebruiken we de gouden standaard in datagedreven processen als leidraad: CRISP-DM. In deel één van deze reeks gaan we in op dit framework en geven we een korte toelichting per stap gezien vanuit de ethische vragen die je hierbij kunt tegenkomen. In de andere artikelen in deze reeks gaan we elke keer dieper in op elke individuele stap.
CRISP-DM
CRISP-DM (Cross-Industry Standard Process for Data Mining) is een raamwerk voor datagedreven processen. Het biedt een planmatige aanpak en is gericht op samenwerking tussen de verschillende rollen die betrokken zijn bij zo’n proces. CRISP-DM is wijdverspreid maar biedt out of the box geen handvatten voor ethiek. Wil je meer weten over CRISP-DM lees dan dit artikel wat hier verder op ingaat.
Aan dit framework willen we een ethische component toevoegen; een opzet waarin de ethische blauwdruk van een proces wordt opgesteld aan de hand van een startpunt van standaardvragen. Daarmee bedoelen we geen lijvig document wat nooit meer bekeken zal worden, maar een leidraad bij de inhoudelijke ethische discussies die gevoerd moeten worden, waarbij de belangrijkste punten van zorg op een korte en bondige manier worden vastgelegd om als inspiratie te kunnen dienen voor toekomstige projecten.
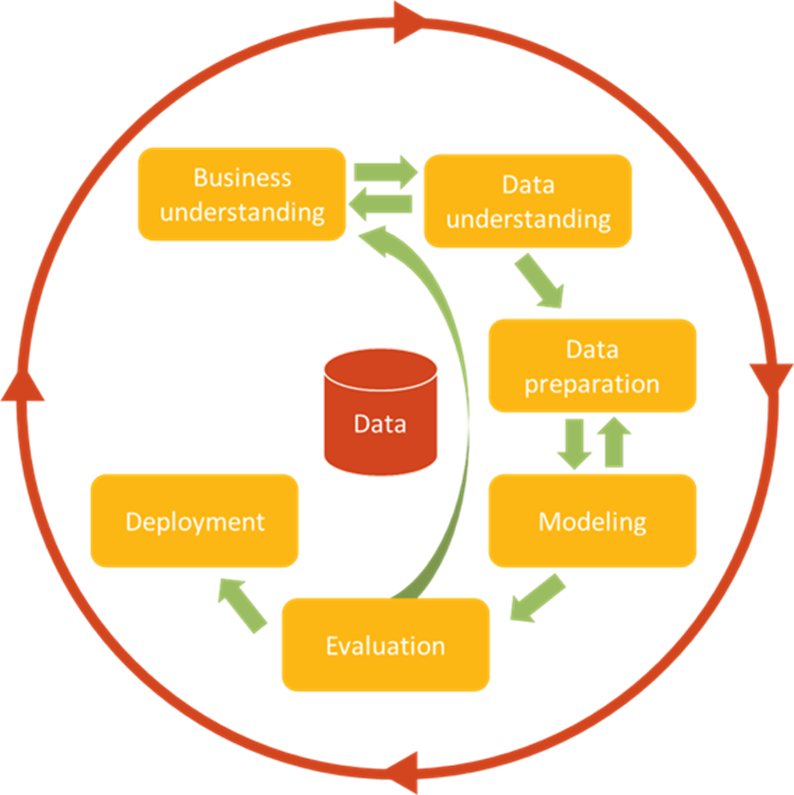
Business understanding
Stap één is het bepalen en begrijpen van de organisatie doelen en de verwachte resultaten van een project. Zorg ervoor dat een brede groep mensen vanuit verschillende bedrijfsonderdelen en verschillende rollen betrokken is bij dit proces. Een van de kernvragen die helder moet worden gemaakt is bijvoorbeeld:
Wie is de eindgebruiker, hoe wordt deze geraakt door de toepassing van deze analyse/model, en welke onbedoelde bijeffecten kunnen er ontstaan?
Bij het beantwoorden van deze vraag zal naar voren komen of tegen het beoogde doel ethische bezwaren kunnen worden gemaakt. Deelvragen die hierbij kunnen helpen zijn bijvoorbeeld:
- Wat is het doel van het project en kunnen hier enige ethische bezwaren tegen bedacht worden?
- Welke data hebben we nodig voor dit project?
- Is die data voor eerdere projecten ook al gebruikt en zijn daar bezwaren in gevonden?
- Met welk doel is de data verzameld en past dit bij dit project?
- Hoe zullen de resultaten uit dit project in de praktijk worden ingezet en welke impact kan dit hebben op de eindgebruiker?
Ethiek moet een thema zijn waar collega’s elkaar op aan kunnen spreken, bij elke stap in een proces. Een enkele ethische bedoordeling per project is dus niet voldoende. Dit is iets wat doorlopend gedaan moet worden.
Data understanding
Deze stap draait om het exploreren en begrijpen van de data die potentieel relevant is voor het project. Hierin is het met name aan de data analist om te achterhalen hoe bruikbaar de data is. Hierbij gaat het over welke data er beschikbaar is, of er voldoende data beschikbaar is, of de data geschikt is voor het gestelde doel, of er veel preparatie moet worden gedaan, etc. Een analist moet zichzelf non stop de vraag stellen of zij hetzelfde kan bereiken met minder data (data minimalisatie), dan wel minder gevoelige data (proportionaliteit). Een model of product wordt immers nooit ‘ethisch’ als de input data al bias heeft. Een analist richt zich zo op de vraag:
Welke bias zit er op voorhand al in de data, en is deze dan wel bruikbaar? Is de data eerlijk ‘verdeeld’ en representatief?
Daarnaast is het ook relevant om stil te staan bij de volgende vragen:
- Is er al bias bekend in de data en kunnen we dan maatregelen nemen om de bias te minimaliseren?
- Zijn er tests die we kunnen doen op het eindresultaat om de invloed van de bias te beoordelen?
- Kan de data informatie in zich “verstopt” hebben (bekend is bijvoorbeeld dat postcodegebied ook een representatie van inkomensniveau in zich kan hebben)?
- Representeert mijn variabele wel wat ik beoog (klopt de definitie die gehanteerd is bij het verzamelen van de data wel met de definitie die ik nodig heb voor dit project)?
Uiteraard geldt ook voor de analist, net als de rest van een organisatie, dat er moet worden stil gestaan bij de vraag of er op voorhand al ethische bezwaren kunnen worden gemaakt tegen de gestelde business goals.
Data preparation
In deze stap gaat de data analist daadwerkelijk aan de slag met het klaarmaken van de data voor de volgende fase. De gevonden uitdagingen uit de voorgaande stap worden zoveel mogelijk aangepakt en opgelost, of er worden maatregelen genomen om ze te minimaliseren. Het doel van deze stap is om aan het einde een betrouwbare en bruikbare dataset te hebben voor de volgende stap van het proces. De analist moet nadenken over hoe bias verwijderd kan worden uit de data. Zij richt zich hierbij bijvoorbeeld op de vraag:
Ben je bewust van eventuele bias die niet te vermijden is en welke stappen zet je om het ontstaan van bias te voorkomen?
Het is hierbij belangrijk om vast te leggen welke potentiële risico’s er voortkomen uit de bekende bias en de manier waarop de resultaten uit deze stap worden ingezet in het werkproces. Daarnaast is het van belang om ook het proces van preparatie zelf vast te leggen, zodat het transparant is welke keuzes gemaakt zijn.
Verdere vragen van belang in deze fase zijn dan bijvoorbeeld ook:
- Welke data moet worden gepseudonimiseerd voordat deze gebruikt kan worden?
- Hoe zorg je ervoor dat data niet toch herleid kan worden tot een persoon na anonimiseren?
- Zorgt het proces van preparatie niet voor het creëren van onbedoelde bias?
Modeling
In de Modeling stap is het wederom met name de data analist die aan zet is. Staar je niet blind op het feit dat deze stap Modeling heet, het gaat hier zeker niet alleen over het ontwikkelen van voorspelmodellen, maar ook over het maken van rapportages en analyses, of over het inzetten van generatieve AI (zoals GPT of andere grote taalmodellen). Het kan dus ook gaan om het maken van een beschrijvende analyse. De centrale vraag hierbij is:
Levert het product ongewenste, oneerlijke of biased resultaten, en snap ik hoe mijn model tot zijn voorspelling komt?
Het is in deze fase belangrijk om telkens na te gaan of de analist al haar aannames heeft gevalideerd. Verdiepende vragen die hierbij helpen zijn bijvoorbeeld:
- Welke principes kan ik gebruiken om mijn output te testen op bias en ethiek? Lees hier meer over hoe je dit kan doen met behulp van de Python package Fairlearn.
- Kan ik unittests ontwikkelen die inzicht geven in specifieke voorbeelden en tot welk resultaat deze zouden leiden (laat bijvoorbeeld aan een gezichtsherkenningsmodel zowel vrouwen als mannen zien bij wijze van test)
- Welke metric gebruik ik om het beste model te kiezen? Welke implicaties heeft de keuze van deze metric? (bijv. als je kanker wil voorspellen accepteer je meer ‘false positives’ dan als je churn wil voorspellen)
Evaluation
In deze stap evalueer je de performance en uitkomsten van het model of de analyse en wordt bepaald in hoeverre deze voldoen aan de gestelde doelen in stap één, de business understanding. Durf jezelf met het team hier de vraag te stellen: wil ik dit publiceren, en wat zouden de reacties zijn? Hier komt dan ook de eerder gestelde vraag terug:
Wat is de impact van de uitkomst van een analyse of model op de gebruiker?
Sta daarbij stil bij vragen als:
- Is er geen onbedoelde bias opgetreden in de data / het model?
- Wat is het gevolg van het publiceren ervan?
- Zijn de uitkomsten transparant en kunnen deze worden uitgelegd?
Deployment
Deze stap behelst de implementatie en livegang van een product. Wees transparant in eventuele beperkingen die een model met zich mee brengt en voor bias kunnen zorgen. Deze heb je in de voorgaande stappen kunnen signaleren en documenteren. Het is daarnaast belangrijk om goed in de gaten te houden hoe een product zich door de tijd ontwikkelt en of er na verloop van tijd niet alsnog ongewenste bijeffecten of resultaten kunnen ontstaan. Mocht dit zo zijn, is het dan duidelijk en transparant waar dit door komt en hoe dit kan worden aangepakt? Een van de monitoringsvragen die na livegang gesteld moet blijven worden is:
Zijn er wijzigingen in de eerdere stappen nodig?
Besef dat nieuwe factoren het resultaat van de toepassing kunnen beïnvloeden en alsnog een ongewenste impact op bijvoorbeeld de privacy van de eindgebruiker kunnen veroorzaken. Denk daarom dan ook na over vragen als:
- Wat zijn de lange termijn gevolgen van de gemaakte keuzes en bij de inzet van de data?
- Hoe wordt de data opgeslagen en welke invloed heef dit op het gebruik ervan richting de toekomst?
Outro
In dit eerste artikel in onze reeks over ethisch datagedreven werken hebben we de eerste praktische handvatten gegeven om meer bewustwording te creëren en stil te staan bij ethiek in jouw organisatie. We willen hiermee vooral laten zien dat ethisch werken nooit bij één persoon of bij een specifiek onderdeel van het bedrijf ligt, maar juist iets is waarvan je organisatie doordrenkt zou moeten zijn.
In onze volgende artikelen gaan we dieper in op de verschillende rollen binnen een organisatie en kleuren we het geschetste model hierboven verder in. Hoe ga je bijvoorbeeld het gesprek rondom ethiek aan vanuit de verschillende rollen?




